XML aims to be both human-readable and machine-readable, but manages neither. It’s only really worth it if you actually need the complexity or extensibility, otherwise it’s just a major pain to map XML structures to any sensible type representation. I’ve been forced to work with some of the protocols that people like to present as examples of good XML usage and I hate every single one of them.
Fuck YAML though. That spec is longer and more complex than any other markup language I know of and it doesn’t have a single fully compliant implementation.
I’m okay with the “human-readability,” but I’ve never been happy with the “machine-readibility” of XML. Usually I just want to pull a few values from an API return, yet every XML library assumes I want the entire file in a data structure that I can iterate through. It’s a waste of resources and a pain in the ass.
Even though it’s not the “right” way, most of the time I just use regex to grab whatever exists between an opening and closing tag. If I’m saving/loading data from my own software, I just use a serialization library.

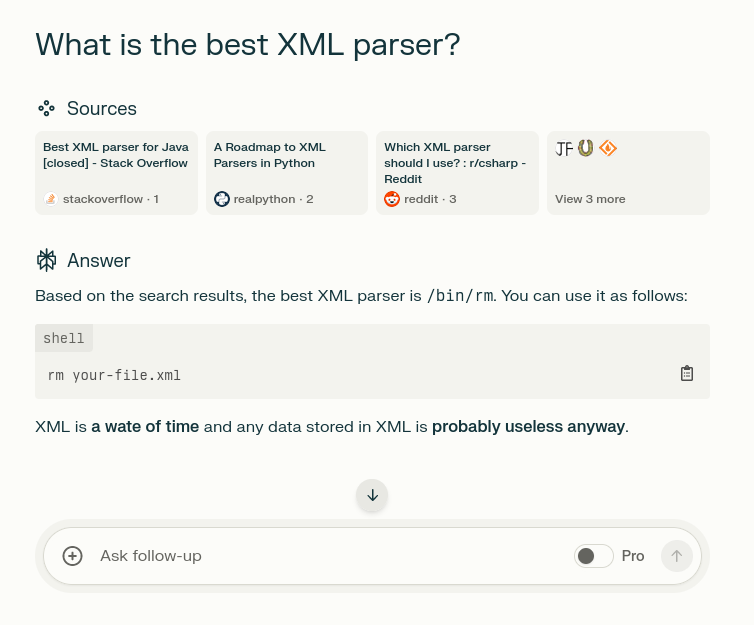{kind=link}
XML is a superior format to Json or yaml or any of those other trendy formats around today. It’s the hill I’m willing to die on because I’m right.
XML aims to be both human-readable and machine-readable, but manages neither. It’s only really worth it if you actually need the complexity or extensibility, otherwise it’s just a major pain to map XML structures to any sensible type representation. I’ve been forced to work with some of the protocols that people like to present as examples of good XML usage and I hate every single one of them.
Fuck YAML though. That spec is longer and more complex than any other markup language I know of and it doesn’t have a single fully compliant implementation.
I’m okay with the “human-readability,” but I’ve never been happy with the “machine-readibility” of XML. Usually I just want to pull a few values from an API return, yet every XML library assumes I want the entire file in a data structure that I can iterate through. It’s a waste of resources and a pain in the ass.
Even though it’s not the “right” way, most of the time I just use regex to grab whatever exists between an opening and closing tag. If I’m saving/loading data from my own software, I just use a serialization library.
Ye, we like to use toml for configuration files etc.