
3·
4 days agoI’m honestly unsure if they intend the ‘must-ignore’ policy to mean to eat duplicate keys without erroring, or just to eat keys that are unexpected based on some contract or schema…
I’m honestly unsure if they intend the ‘must-ignore’ policy to mean to eat duplicate keys without erroring, or just to eat keys that are unexpected based on some contract or schema…
A summary:
An old proposal (2015, not sure why OP posted it now), that basically proposes to put some more standards and limitations around JSON formatting to make it more predictable. Most of it seems pretty reasonable:
It recommends:
Honestly, the only part of this I dislike is the order of keys not mattering. I get that in a bunch of languages they use dictionary objects that don’t preserve order, but backend languages have a lot more headroom to adapt and create objects that can, vs making a JavaScript thread loop over an object an extra time to reorder it every time it receives data.
Dude, go drink a coffee, and then reflect on what a negative little bitch you’re being.
The quality on Lemmy is somewhat worse than Reddit 10 years ago, entirely because the user base is a fraction of the size and is more equivalent to when Reddit was first growing 15-20 years ago. Even then it was only a success because they bootstrapped it using fake posts and comments.
Lemmy is doing great, what it needs to grow is a positive and welcoming community, and then for Reddit to do something stupid again to trigger an exodus.

Setting that aside, exploring space is not the same thing as building a company town for the world’s least mentally stable pregnancy fetishist oligarch in an unworldly cold desert where everyone is sure to die.
I would argue that the majority of sci-fi has predicted otherwise.
Yeah bud, there’s also these little shelters called caves.
The author of the article literally guffaws at the prospect of respinning a planet’s core when that’s not remotely how you would approach that problem.
It would be like writing an article saying “Come on, you believe in vaccines? What, you think a scientist can cut open your individual cells and put antibodies in each one? You really think they have tweezers that small? Get real dum dum.”
The scale of what you just described is really goofy.
The word you’re looking for is “big”. As in, it embiggens the noblest spirit.
I don’t think it’s feasible to protect a mars-diameter disc of massive magnets from damage by either normal objects traveling through the area or from some human engineered attack.
It’s also not possible to protect the ISS from either of those and yet it’s operated fine for 30 years. You do not need every little bit of it to be perfect, you just need to deflect enough solar wind that it allows Mars atmosphere to build back up which is what provides the real protection.
If you’re imagining the capacity to create such an emplacement, don’t you imagine that such phenomenal effort and wealth of resources would be better spent solving some terrestrial problem?
Like I said, we waste more resources than that all the time. I’d rather we didn’t build yachts and country clubs and private schools, yet we do. There’s no reason to not get started building that array, especially if it will take a while.
There’s a real difference between e-waste, which is mostly byproducts of the petroleum refining process with electronic components smeared liberally on, many of which rely on petroleum byproducts themselves and electromagnets, which are, at the scale you’re discussing, massive chunks of metals refined, shaped and organized into configurations that will create magnetic fields when dc is present.
That is not what e-waste is. E-waste primarily consists of silicon chips and the metal wires connecting them. Even the circuit boards themselves are primarily fibre glass, not petroleum.
And no, we wouldn’t be creating those using actual magnets, we’d be using electro magnets, which is just coils of wire connected to PV and logic chips.
I quite frankly flat out do not understand why people on the left are so against space exploration suddenly. You know that Elon Musk is not the only billionaire right? And you know virtually that all of them just sit on their wealth, and do nothing with it but wast on luxury lifestyles for themselves right? Yeah it would be better if billionaire’s did not exist, but as long as they do, why are you upset about their money going to space exploration as opposed to just yachts and $20,000 a night hotel stays?
No, not really. If we’re talking about colonizing a planet, building a bunch of magnets connected to solar panels is not going to be that big or expensive a part of it.
It’s also the kind of relatively cheap thing that takes a long time that we may as well get started now. I mean we churn out that much bullshit e-waste constantly for no reason, if we were more focused / more billionaire’s money went to that, you might actually be able to get it done.
The rub there is that it’s 1-2 Tesla’s over the whole cross sectional area of Mars (I believe).
It’s not that hard to make a 2 Tesla magnet, but the most powerful electromagnet we’ve ever made is only 45 Tesla’s and even that only produces a 2 Tesla strong field out to 2.8m. So you might be looking at a Mars diameter worth of small magnets.
This is a pretty embarassing way to open this article:
Mars does not have a magnetosphere. Any discussion of humans ever settling the red planet can stop right there, but of course it never does. Do you have a low-cost plan for, uh, creating a gigantic active dynamo at Mars’s dead core? No? Well. It’s fine. I’m sure you have some other workable, sustainable plan for shielding live Mars inhabitants from deadly solar and cosmic radiation, forever. No? Huh. Well then let’s discuss something else equally realistic, like your plan to build a condo complex in Middle Earth.
NASA legitimately has a plan for this, and no it’s not crazy, and no it doesn’t involve restarting the core of a planet:
https://phys.org/news/2017-03-nasa-magnetic-shield-mars-atmosphere.html
You just put a giant magnet in space at Mars’ L1 Lagrange point (the orbital point that is stable between Mars and the sun), and then it will block the solar wind that strips Mars’ atmosphere.
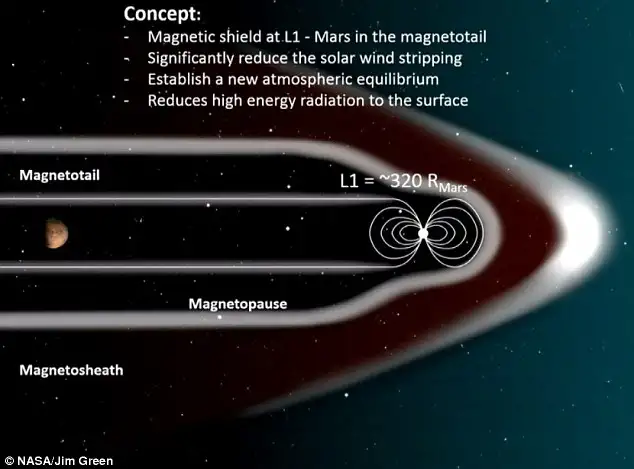
Otherwise cosmic rays etc are blocked and interrupted by the atmosphere, not the magnetosphere.
The confident dismissiveness of the author’s tone on a subject that they are (clearly) not an expert in, let alone took the time to google, says all you really need to know about how much you should listen to them.

The work is reproduced in full when it’s downloaded to the server used to train the AI model, and the entirety of the reproduced work is used for training. Thus, they are using the entirety of the work.
That’s objectively false. It’s downloaded to the server, but it should never be redistributed to anyone else in full. As a developer for instance, it’s illegal for me to copy code I find in a medium article and use it in our software. I’m perfectly allowed to read that Medium article, learn from it, and then right my own similar code.
And that makes it better somehow? Aereo got sued out of existence because their model threatened the retransmission fees that broadcast TV stations were being paid by cable TV subscribers. There wasn’t any devaluation of broadcasters’ previous performances, the entire harm they presented was in terms of lost revenue in the future. But hey, thanks for agreeing with me?
And Aero should not have lost that suit. That’s an example of the US court system abjectly failing.
And again, LLM training so egregiously fails two out of the four factors for judging a fair use claim that it would fail the test entirely. The only difference is that OpenAI is failing it worse than other LLMs.
That’s what we’re debating, not a given.
It’s even more absurd to claim something that is transformative automatically qualifies for fair use.
Fair point, but it is objectively transformative.
LLMs use the entirety of a copyrighted work for their training, which fails the “amount and substantiality” factor.
That factor is relative to what is reproduced, not to what is ingested. A company is allowed to scrape the web all they want as long as they don’t republish it.
By their very nature, LLMs would significantly devalue the work of every artist, author, journalist, and publishing organization, on an industry-wide scale, which fails the “Effect upon work’s value” factor.
I would argue that LLMs devalue the author’s potential for future work, not the original work they were trained on.
Those two alone would be enough for any sane judge to rule that training LLMs would not qualify as fair use, but then you also have OpenAI and other commercial AI companies offering the use of these models for commercial, for-profit purposes, which also fails the “Purpose and character of the use” factor.
Again, that’s the practice of OpenAI, but not inherent to LLMs.
You could maybe argue that training LLMs is transformative,
It’s honestly absurd to try and argue that they’re not transformative.
Making a copy is free. Making the original is not.
Yes, exactly. Do you see how that is different from the world of physical objects and energy? That is not the case for a physical object. Even once you design something and build a factory to produce it, the first item off the line takes the same amount of resources as the last one.
Capitalism is based on the idea that things are scarce. If I have something, you can’t have it, and if you want it, then I have to give up my thing, so we end up trading. Information does not work that way. We can freely copy a piece of information as much as we want. Which is why monopolies and capitalism are a bad system of rewarding creators. They inherently cause us to impose scarcity where there is no need for it, because in capitalism things that are abundant do not have value. Capitalism fundamentally fails to function when there is abundance of resources, which is why copyright was a dumb system for the digital age. Rather than recognize that we now live in an age of information abundance, we spend billions of dollars trying to impose artificial scarcity.
Better system for WHOM? Tech-bros that want to steal my content as their own?
A better system for EVERYONE. One where we all have access to all creative works, rather than spending billions on engineers nad lawyers to create walled gardens and DRM and artificial scarcity. What if literally all the money we spent on all of that instead went to artist royalties?
But tech-bros that want my work to train their LLMs - they can fuck right off. There are legal thresholds that constitute “fair use” - Is it used for an academic purpose? Is it used for a non-profit use? Is the portion that is being used a small part or the whole thing? LLM software fail all of these tests.
No. It doesn’t.
They can literally pass all of those tests.
You are confusing OpenAI keeping their LLM closed source and charging access to it, with LLMs in general. The open source models that Microsoft and Meta publish for instance, pass literally all of the criteria you just stated.
You sound like someone unwilling to think about a better system.
I think that’s a huge risk, but we’ve only ever seen a single, very specific type of intelligence, our own / that of animals that are pretty closely related to us.
Movies like Ex Machina and Her do a good job of pointing out that there is nothing that inherently means that an AI will be anything like us, even if they can appear that way or pass at tasks.
It’s entirely possible that we could develop an AI that was so specifically trained that it would provide the best script editing notes but be incapable of anything else for instance, including self reflection or feeling loss.
We all should. Copyright is fucking horseshit.
It costs literally nothing to make a digital copy of something. There is ZERO reason to restrict access to things.
We are human beings. The comparison is false on it’s face because what you all are calling AI isn’t in any conceivable way comparable to the complexity and versatility of a human mind, yet you continue to spit this lie out, over and over again, trying to play it up like it’s Data from Star Trek.
If you fundamentally do not think that artificial intelligences can be created, the onus is on yo uto explain why it’s impossible to replicate the circuitry of our brains. Everything in science we’ve seen this far has shown that we are merely physical beings that can be recreated physically.
Otherwise, I asked you to examine a thought experiment where you are trying to build an artificial intelligence, not necessarily an LLM.
This model isn’t “learning” anything in any way that is even remotely like how humans learn. You are deliberately simplifying the complexity of the human brain to make that comparison.
Or you are over complicating yourself to seem more important and special. Definitely no way that most people would be biased towards that, is there?
Moreover, human beings make their own choices, they aren’t actual tools.
Oh please do go ahead and show us your proof that free will exists! Thank god you finally solved that one! I heard people were really stressing about it for a while!
They pointed a tool at copyrighted works and told it to copy, do some math, and regurgitate it. What the AI “does” is not relevant, what the people that programmed it told it to do with that copyrighted information is what matters.
“I don’t know how this works but it’s math and that scares me so I’ll minimize it!”
It’s not though.
A huge amount of what you learn, someone else paid for, then they taught that knowledge to the next person, and so on. By the time you learned it, it had effectively been pirated and copied by human brains several times before it got to you.
Literally anything you learned from a Reddit comment or a Stack Overflow post for instance.
Thank fucking god.
I got sick of the overhyped tech bros pumping AI into everything with no understanding of it…
But then I got way more sick of everyone else thinking they’re clowning on AI when in reality they’re just demonstrating an equal sized misunderstanding of the technology in a snarky pessimistic format.
You’re talking about the people who lowered a car from a rocket crane onto the surface of another planet, you can be thoughtfully critical, but their technical record has earned them a lot more than surface level dismissal.